


From January 2023, TinyMCE no longer offers Real-Time Collaboration (RTC) for new customers. For Existing customers, we'll be in contact to discuss options. Please reach out to your Account Manager if you are a customer using RTC, and you have any questions about the plugin.
This is the first in a series of blog posts documenting the TinyMCE RTC journey and decisions along the way. Next post: Collaboration needs a clean Slate.
If you dig below the surface of any real-time collaboration solution you're likely to start hearing about the terms OT (Operational Transformation) and CRDT (Conflict-free Replicated Data Type). For a team trying to build a real-time collaboration solution, the first question to ask is "which of these two acronym mouthfuls should I use"? Followed quickly by "what on earth do these acronym mouthfuls mean"?
The full response to these questions took me about a month to answer. There is a vast collection of reading material available; navigating that rabbit hole was a fun journey. I will include links at the end to the research and reading material I used to form my conclusions.
At a very high level, this is what we're dealing with:
- OT relies on an active server connection (not quite correct but we'll get to that in a moment) to coordinate and guarantee all clients operate correctly.
- CRDT is capable of working peer-to-peer with end-to-end encryption; if a server is used at all it only needs to coordinate connections between clients. It is resilient to transient network connections. It even works if clients go offline for a period of time, make changes, and synchronise when the network returns.
Sounds like an easy decision, right? Isn't CRDT the obvious and (for privacy reasons) the only sane choice? Well, nothing's ever that easy. There is a reason Google, Microsoft, CKSource and many others depend on OT. Tiny has chosen to also build our solution around OT; I'd like to discuss the difference between these two algorithms in more detail and how the CRDT caveats lead us to stick with OT.
Collaboration Algorithms
The general theory of collaboration algorithms is to transmit changes between users with the goal of "eventual consistency". If multiple users make changes at the same time their copies of the document might look different for a while, but eventually every user's view will converge to be the same. This is done through what I call a "baseline"; incoming changes are integrated into the local data to form new baselines and local changes are sent based on the current baseline.
The difficulty in collaboration rises from the restriction that clients cannot check whether the baseline they've calculated is the same as other clients. To do so would require collaboration on top of collaboration and it's turtles all the way down. The smallest bug in a collaborative implementation can lead to divergence; in a rich text editor diverged documents will quickly lead to nonsensical changes as operations are passed around. The CKEditor team wrote a really nice post about what can go wrong in diverged documents last year.
This is starting to sound like an impossible problem, but after 30 years of research the established technology for simple collaboration cases is very mature. When the TinyMCE development team began investigating various technologies for collaboration, the editor was able to collaborate on unformatted paragraphs (using plain text transformations) within days.
Operational Transform (OT)
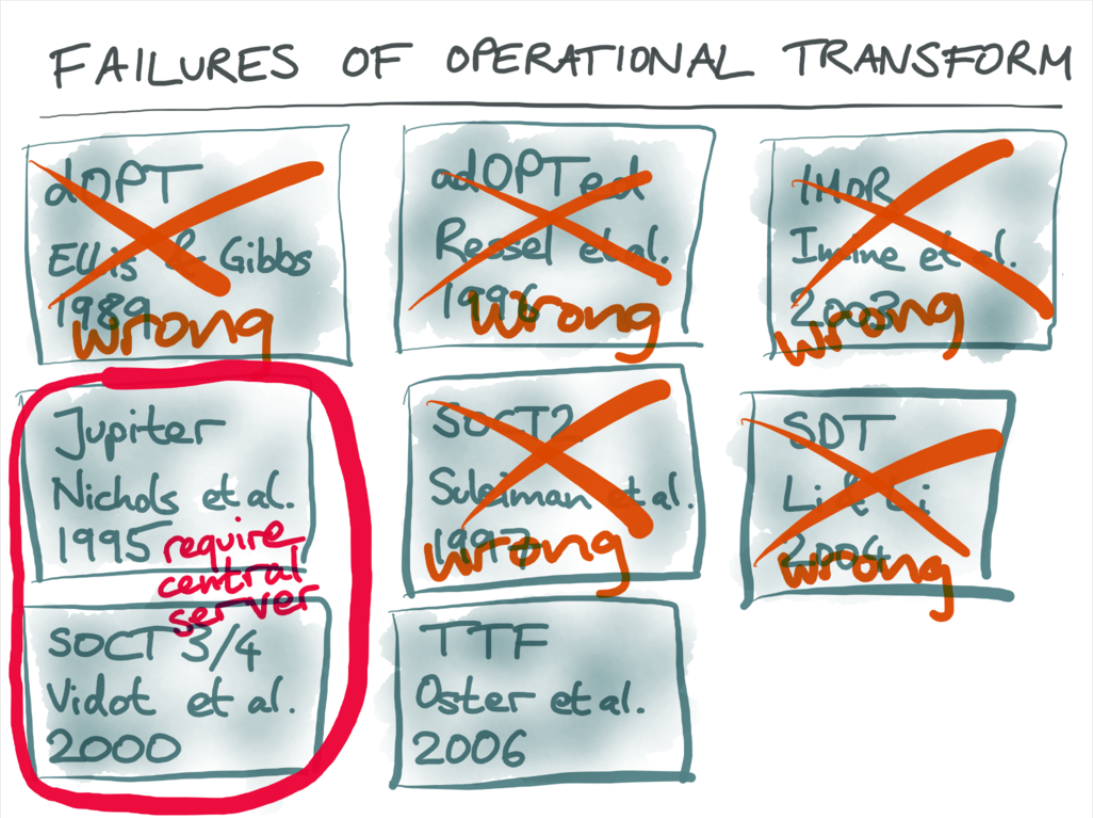
Operational Transformation, originally proposed in 1989, has had many forms over the years. The original vision did not require a server at all. However, as more and more research was published on the topic, and most of it was proven wrong, it became clear that OT had too many edge cases.
Credit: Martin Kleppmann, 2018
In OT, every user action is broken down into one or more operations. These operations are transmitted between clients along with their baseline reference; if two users perform actions at the same time, incoming operations must be transformed to include the local operations that have happened since that baseline. They are then applied locally and form the new baseline.
This constant transformation of operations turned out to have too many edge cases where clients were found to not produce the same baseline (the "wrong" papers above). When that happens, the clients will never converge on the same result and break the fundamental assumption of collaboration.
Only two reliable forms of OT have survived the test of time:
- Server-based OT, splitting multi-user collaboration into groups where each client pairs individually with the server. The server coordinates the document state and operation list to ensure that transformation only ever occurs within these pairs, thus avoiding the complexity (and edge cases) of three-way transforms.
- OT with what's known as "transform property 2". CP2/TP2 finally gave the community a provably correct multi-way transformation algorithm, but it turned out to be so complex that very few data structures have working TP2 implementations.
I don't have a clear picture of exactly when or how the community decided to move on from OT, but I think it was pretty clear that OT had reached the limit of what research could offer and a new direction emerged.
Conflict-free replicated data type (CRDT)
The Conflict-free replicated data type began popping up around 2006, was formally defined in 2011, and has quickly become the darling child of the distributed computing industry. CRDT offers everything OT promised and delivers it with confidence backed by years of proven reliability in databases.
The magic of CRDT is due in large part to how it breaks down data into such small pieces that it generally doesn't need to transform the change itself, only the position of the change. For example, text data collaboration with CRDT treats every character as a separate entity.
With this restriction, the current state of CRDT research supports collaboration on two main types of data:
- Plain text
- Arbitrary JSON structures (using a separate plain text CRDT for each text value)
And that second point, dear reader, has tied in nicely to the rise of content management that stores JSON document data instead of HTML.
The limitations of CRDT are similar to what happened when the TP2 restriction was proposed for OT; the difficulty is in the data type. It is not as difficult as TP2 - there is a working OT+TP2 for JSON, but my impression is the CRDT implementation was easier to achieve - but it's still only appropriate for simple use cases.
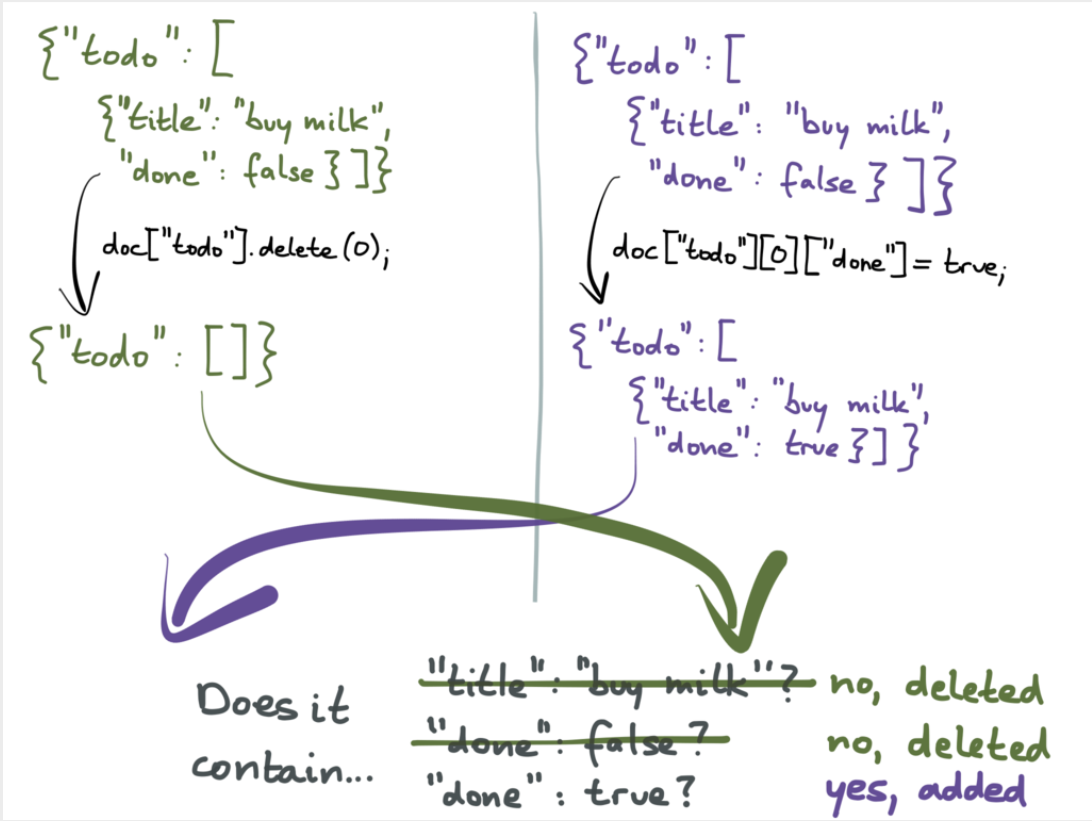
When it comes to more advanced structures such as rich text editing, the crux of the problem with CRDTs is user intent. Working at such a low level provides an easier guarantee of eventual consistency, but you lose sight of the big picture. For example in OT we can define a "split text node" operation which can be complicated to transform but is very well understood to have certain properties in a rich text editor. Whereas in CRDT, the changes are more data-focussed and it becomes very clinical. A good example is splitting a text node. Think about what that might take at the data level:
- Remove text after the split point in the node
- Insert a new sibling text node after the current node containing the removed text
This might not be exactly how CRDT algorithms represent these changes, but my point is they do not transmit the intent. OT trades complexity for the ability to capture the intent; CRDT has less complexity but can only guarantee all clients end with the same data - however that data might not be the intended structure, or even valid for your schema.
Credit: Martin Kleppmann, 2016
The effect of this trade-off is that while there are some editors available today with support for collaboration using CRDT, every single one of them has compromises in depth of features and user experience.
If you can show me a rich text editor with support for CRDT, I can show you why I struggle to call it a "rich" text editor. Perhaps we should call them moderately wealthy text editors. Limiting the breadth of HTML capability for ease of collaboration is a popular trend, but not one that we wish to engage with for TinyMCE.
In the worst case, when applying CRDT mechanisms to a full rich text editor, the user experience can be compromised due to the lack of intent. During my research I was already leaning towards OT, but this video shows the point at which I decided CRDT was not ready for our needs. This is a convergence.io demo showing their collaboration server linked to the Froala rich text editor.
This is the exact "split node" scenario I described earlier; applying bold near the start of a text node necessarily has to split the text node into three parts (before, bold, and after). With a CRDT implementation, when the collaborating user's cursor is in the "after" section, the application of bold recreates the text node and the user has a poor experience.
Conclusions
While my example is very simple and could be managed so the cursor doesn't move, I saw it as a sign of unknown and potentially far greater pain. The risks of finding an unsolvable issue on that path are too great, compared to the very complex but known feasibility of Operational Transformation on a rich text model.
CRDT is the holy grail of collaboration, it's an active area of research, and the prospect of peer-to-peer editing with end-to-end encryption is an exciting one. The technology isn't ready for our needs yet, but I believe in the future some incredible products will be made possible. In the meantime TinyMCE will rely on OT for collaboration, coming later this year.
Research links (in no particular order):
Conflict Resolution for Eventual Consistency, Martin Kleppmann 2016
CRDTs and the Quest for Distributed Consistency, Martin Kleppmann 2018
Lessons learned from creating a rich-text editor with real-time collaboration, CKSource 2018
Why CRDT didn't work out as well for collaborative editing xi-editor, 2019 Hacker News thread (links to github)
Understanding and Applying Operational Transformation, Daniel Spiewak 2010
Creating a Collaborative Editor, Pierre Hedkvist 2019
A Conflict-Free Replicated JSON Datatype, Martin Kleppmann and Alastair R. Beresford 2017
Towards a unified theory of Operational Transformation and CRDT, Raph Levien 2016
Data Laced with History: Causal Trees & Operational CRDTs, Alexei Baboulevitch 2018
Visualization of OT with a central server, Tim Baumann 2012
Real Differences between OT and CRDT for Co-Editors, 2018 Hacker News thread (links to paper)*
* This last paper was updated in 2019 and split into three parts:


