


From January 2023, TinyMCE no longer offers Real-Time Collaboration (RTC) for new customers. For Existing customers, we'll be in contact to discuss options. Please reach out to your Account Manager if you are a customer using RTC, and you have any questions about the plugin.
Last month, Tiny released its real-time collaboration (RTC) plugin for TinyMCE as a closed beta. Those participating in it will very quickly notice a fairly radical departure from other OT-based collaboration solutions: mandatory end-to-end encryption.
Every snapshot, operation, and presence update is secured by AES-GCM symmetric encryption in addition to the usual transport security. The associated keys are never shared with our servers. Our servers do hold the document content for all collaborations, but without those keys the content cannot be decrypted by the server. AES-256 encryption is hardware accelerated on modern CPUs, so this is all performed smoothly and efficiently without a user-perceptible performance impact.
This encryption is required for our cloud service and also our self-hosted solutions when they become available.
The engineering team at Tiny cares a lot about security and privacy in our products, which is one of the reasons why the identity tokens used to identify users to Tiny Drive (and now RTC) require asymmetric signatures. There’s no reason a developer using these services should need to share those signing keys with us, so we’ve gone out of our way to ensure they don’t.
Our RTC server goes a bit further though. Likely, no system you’ve ever used to write a document collaboratively uses end-to-end encryption. So when Tiny set out to solve this problem, why did we feel this was necessary?
It’s not our data
TinyMCE is used by professionals and knowledge workers around the world. But while they are our users, they’re generally not our customers. We sell TinyMCE to organizations that use it to enhance the functionality of their systems, whether they be ISVs, governments, or private companies. They certainly want a good content creation experience for their users, but that’s not their only priority.
TinyMCE is used by a lot of organizations for Very Serious Things, and we are under no illusion that they are inclined or at liberty to share the content TinyMCE helps them to create and manage with us. Often they (or their regulators) want that content under the tightest control possible. TinyMCE has service-supported plugins to do image transformation and spell checking, and while Tiny Cloud retains the content sent only so long as is needed to fulfill requests, many companies choose to self-host those services to remove even that limited sharing.
RTC presented a bit of a problem then, because once we realized CRDTs were not a good choice, we knew we would need an OT server that was aware of all the operations in the collaborative session. For cloud-hosted customers, this meant we would need to hold their documents on our servers. For self-hosted customers, it would mean that no matter how securely they might store and process their data currently, they would need to store a copy of actively-edited documents with our server and keep our server secure too. For long-running sessions, those documents could be there for days, so everybody’s internal security analyses would have to treat the RTC server almost as carefully as their primary data store.
(We’re assuming here that there are two places holding the document data, because as easy, neat, and simple it might seem for our RTC server to hold the primary copy of the document like Google Docs, in practice, many organizations would be unlikely to accept that.)
The easiest way to keep a secret is not to know it in the first place, so we decided the best possible way to satisfy these security concerns was for us never to have a copy of the content we can read.
There was a secondary benefit to taking this approach though...
Maintenance
Many OT-based RTC servers need to be able to carry out the same operational transformations as any connected client. This is fundamental to any server modeled after the original Jupiter paper, including Apache (formally Google) Wave and ShareDB. If we took this approach, it raised two maintenance issues:
- The server needs to know the transformations, so every time the client is updated, the server needs to be updated first. If there are multiple versions of the transformations, then the server needs to know about all the versions used by currently-supported clients.
- The server needs to be able to perform the transformations, so either the server must support running the client transformations natively (e.g. NodeJS running JavaScript) or two implementations are required.
(1) would be OK for our cloud services, but upgrading the server in-sync with the client is an extra burden we wanted to avoid for our self-hosted customers. This isn’t just because we value their time; we encourage customers to upgrade TinyMCE on a regular basis.
Over time we fix a lot of bugs and the editor gets better. It’s easier for us to demonstrate the value of a TinyMCE subscription when you’re using the latest version. Building a collaboration solution that requires scheduling server upgrades before every client upgrade is not going to help us with that outcome.
(2) is more of an architectural issue at Tiny. Two transform implementations would be too costly to maintain, and Tiny does not run a lot of NodeJS servers. We prefer Haskell and Scala for their strong safety and parallelism support. We could run NodeJS or embed a JS engine within Haskell or Scala, but this was going to add complexity to a server that we really wanted to be as simple as possible in order to scale well on both cloud and self-hosted installs.
So the answer is simple, right? We just don’t do the transforms on the server. That allows us to do end-to-end encryption and skip the maintenance hassles!
Earlier though, we said server transforms were fundamental, so what made us think we could do without them?
The other way to do OT
Let’s go back to the slide screencap by Martin Kleppmann that featured in our earlier blog post on OT vs CRDT:
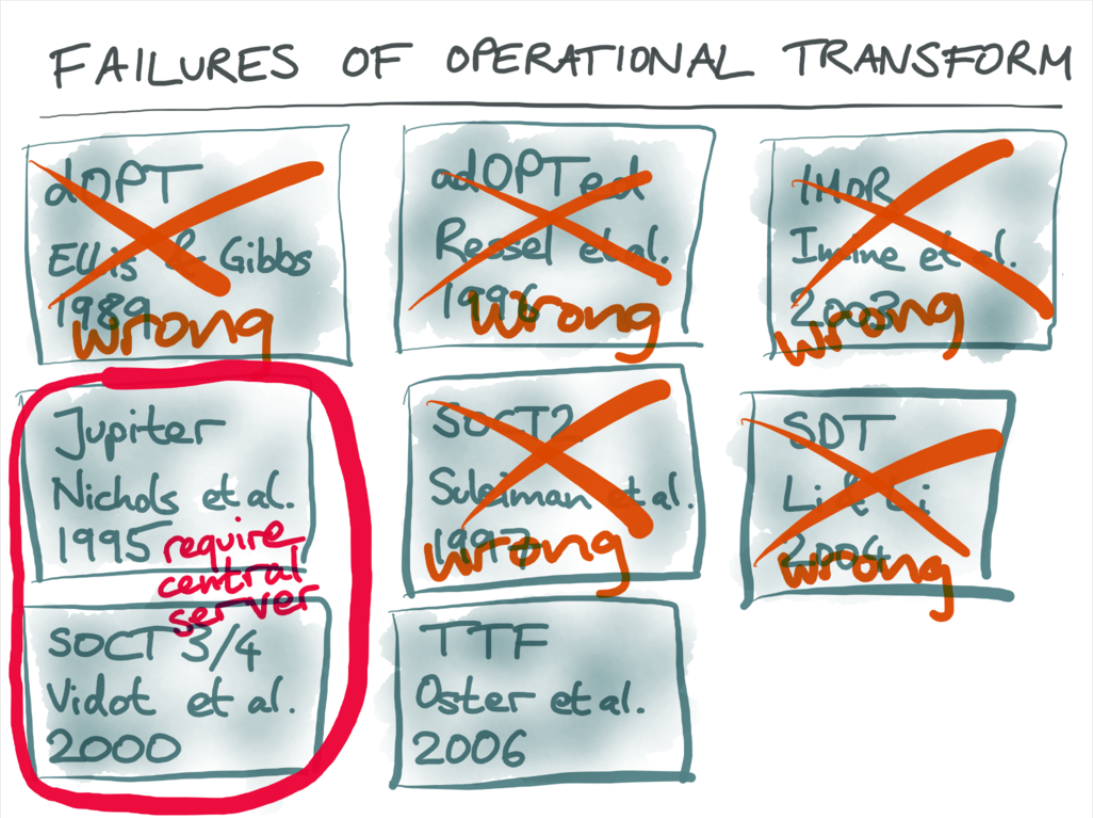
The SOCT 3 & 4 algorithms are not like Jupiter, in that the server is not really required to store operations at all. The server assigns operations an ID in a continuous global (total) order, and clients then do the required transformations themselves to conform to that ordering. Like Jupiter, this avoids three-way transformation problems because the server is ultimately determining the “true” order of operations as it sees them, and each client is individually converging towards that ordering. Unlike Jupiter, only the clients do the transforming, not the server.
Unfortunately, SOCT3 requires reverse transformations, which (even if the literature agreed they were sound) would be a real pain to implement. SOCT4 does not, but it has what might be an even bigger problem: it’s not resilient to client crashes.
In SOCT4, an ID in the global total order is assigned to an operation, then later the client broadcasts the operation to other clients once it has been transformed by all the operations prior to that ID. This raises a fairly obvious question of what happens if the client doesn’t broadcast the operation. Fortunately, the original paper covers that:
Collaboration is suspended but each user may continue to work separately. Collaboration will be resumed as soon as the sequencer is recovered. The effect is the same when a timestamped operation is not broadcast by a malicious site. In other words, the collaboration provided by SOCT3 and SOCT4 cannot be partial: either all sites collaborate or each one works separately.
A situation where one client having a sudden network outage brings the entire collaborative session to its knees isn’t really what we had in mind. Any other options?
SOCT5
One of the primary authors of the SOCT4 paper was Nicolas Vidot, who published his Doctoral Thesis to the University of Montpellier in September 2002: “Convergence des Copiesdans les Environnements Collaboratifs Répartis” (Convergence of Copies in Distributed Collaborative Environments). In this thesis, in addition to noting flaws in SOCT3, he also outlined an additional algorithm, SOCT5.
None of Tiny’s engineers working on RTC are fluent in French, but fortunately, machine translation is a lot better now than in 2002, so we were able to learn that:
“The second algorithm, SOCT5, is an evolution of SOCT4 that uses the immediate broadcast of operations. This technique makes the algorithm a bit more complex but has the significant advantage of making the operation more efficient by allowing concurrent broadcasts between sites.”
SOCT5 allows immediate broadcast because, unlike in SOCT4, the receiving clients do the remaining transformations required to put the operation into its place in global total order. More computations are required in the system as a whole, but the system is considerably more robust. The server can be built to issue an ID when it sees the operation broadcast, avoiding a single crashed client halting the collaboration.

A sample of SOCT5 pseudocode from "Convergence des Copies dans les Environnements Collaboratifs Répartis".
Unfortunately, SOCT5 is complicated. In part, this is because it is trying to be as close to a peer-to-peer protocol as possible, but also because it is lacking some of the pragmatic improvements to OT servers made by Google Wave later in that decade. Tiny’s primary gain from SOCT5 was the general concept, which helped convince us what we wanted was possible.
Tiny’s RTC server
Our RTC server is something of a hybrid between SOCT5 & Jupiter. Operations are still stored on the server like Jupiter, but mainly to simplify the process of clients joining and leaving the collaborative session. Like SOCT5, every operation is assigned an ID in global total order.
While early versions of the server required all operations to be replayed on top of the initial document snapshot when a client joined (like op-based CRDT), we now support clients reaching agreement on updated global snapshots. This means new clients often have far fewer operations to apply than they would with CRDT. This regular computation of a global snapshot state also allows greatly-enhanced error checking compared with a pure Jupiter-style server. The client can detect when it has failed to converge with other clients, disconnect itself from the session, and prevent further user input that might be lost.
Most importantly, the server facilitates the collaborative session without any knowledge of what the bytes in these operations and snapshots are, or even the cursor position of clients. It knows of user IDs and document IDs, but it’s straightforward for a developer to provide synthetic IDs for collaboration if that is desirable. A client-supplied key hint field is available for sessions to make key rotation easier, but as with any genuine E2E encryption we won’t know how it is used.
Fast, secure & built to scale
By keeping all the OT-related computations on the client, Tiny RTC avoids centralizing those processing overheads inside a data center and instead moves them out to the edge. Whether you’re adding collaboration to an existing product or building a new experience from the ground up, we’re confident that in 2021 it will be a server that can scale up and out to your needs without sacrificing privacy and security.
Get started with real-time collaboration in your apps
During the closed beta period, we’re offering limited access to select customers to check out the next evolution of real-time collaboration.
If you'd like to find out more about what's coming up for TinyMCE, check on the TinyMCE Roadmap. You can register an new idea, and see which suggestions are entering research and development.
Otherwise, stay informed of our progress by registering your interest and following our blog for the latest updates.



